AI Weekly Newsletter (New open models)
Highlights
- OpenAI experiences significant leadership changes
- Meta releases Llama 3 models with impressive benchmarks
- Google unveils updated Gemini models with performance improvements and price reductions
- AlphaChip transforms computer chip design using AI
News
OpenAI Leadership Changes
- Top executives leaving OpenAI:
- CTO Mira Murati
- Chief Research Officer Bob McGrew
- Research Leader Barret Zoph
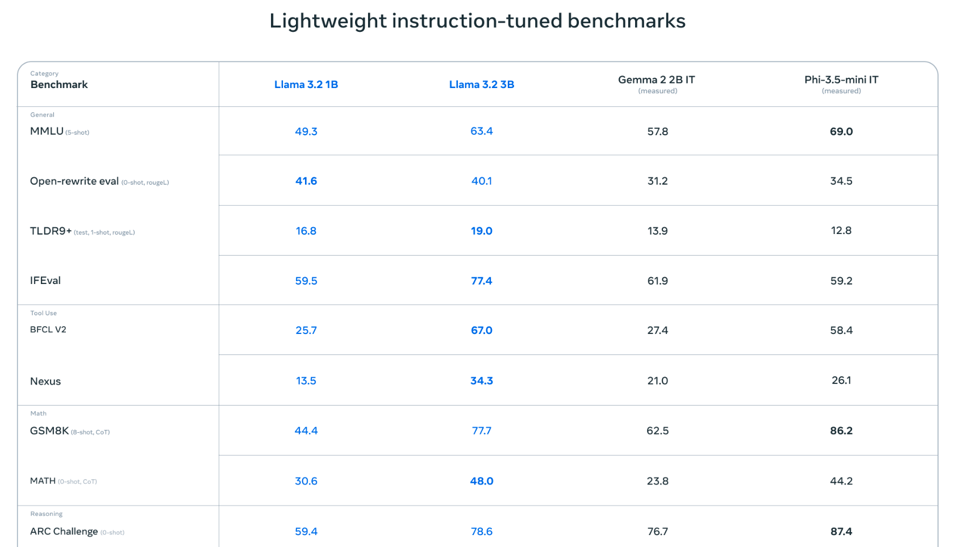
Llama 3.2 Release
- Meta releases new Llama 3.2 models:
- 11B model comparable/slightly better than Claude Haiku
- 90B model comparable/slightly better than GPT-4o-mini
- New 128k-context 1B and 3B models competing with Gemma 2 and Phi 3.5
- Tight on-device collaborations with Qualcomm, Mediatek, and Arm
- MMMU Benchmark Leaderboard

Molmo Models by AI2
- Open-source multimodal models outperforming Llama 3.2 in vision tasks
- 7B and 72B model sizes (plus 7B MoE with 1B active params)
- Benchmarks above GPT-4V, Flash, etc.
- Human preference of 72B on par with top API models
- Molmo Blog
- Molmo Models on Hugging Face
- Molmo Paper
Molmo comparison

PixMo Dataset
- High-quality dataset for captioning and supervised fine-tuning
- Created without using VLMs to generate data
- Includes dense captioning and supervised fine-tuning data
- Novel data collection methodology using spoken descriptions
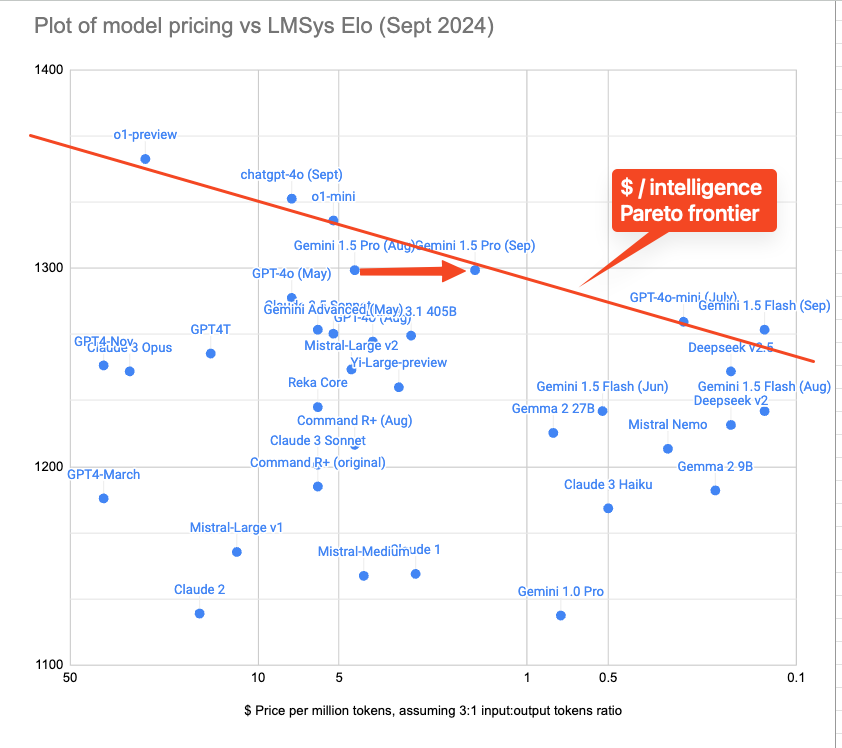
Google’s Gemini 1.5 Updates
- Release of Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002
- Significant improvements:
50% reduced price on 1.5 Pro for prompts <128K
- 2x higher rate limits on 1.5 Flash and ~3x higher on 1.5 Pro
- 2x faster output and 3x lower latency
- Updated default filter settings
- Performance improvements across various benchmarks
- Google AI Studio
- Gemini API Documentation
This is how cost vs intelligent stands:
AlphaChip
- Google’s AI method for designing chip layouts
- Used in the last three generations of Google’s Tensor Processing Unit (TPU)
- Generates superhuman chip layouts in hours instead of weeks or months
- Nature Addendum
- Pre-trained Checkpoint
- DeepMind Blog Post
Research
Elo Uncovered: Robustness and Best Practices in Language Model Evaluation
- Study on the suitability of the Elo rating system for evaluating Large Language Models
- Explores reliability and transitivity axioms in LLM evaluation
- Findings offer guidelines for enhancing the reliability of LLM evaluation methods
- Paper Link
Enhancing Structured-Data Retrieval with GraphRAG
- Introduces Structured-GraphRAG framework for improving information retrieval across structured datasets
- Utilizes multiple knowledge graphs to capture complex relationships between entities
- Case study on soccer data demonstrates improved query processing efficiency and reduced response times
- Paper Link
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
- Comprehensive benchmark for evaluating LLMs’ performance in generating long text
- Categorizes tasks based on Bloom’s Taxonomy
- Proposes HelloEval, a human-aligned evaluation method
- Experiments across 30 mainstream LLMs reveal limitations in long text generation capabilities
- GitHub Repository
Libraries
crawl4ai
- GitHub repository for easy web scraping with LLM-friendly output formats
- Features:
- Supports crawling multiple URLs simultaneously
- Extracts media tags, links, and metadata
- Custom hooks for authentication, headers, and page modifications
- GitHub Repository