AI Newsletter - October 2024
Sarvam: Breaking New Ground in Indian Language AI
India’s linguistic diversity has long posed a challenge for AI development, but Sarvam-1 is changing the game. This 2-billion parameter language model specifically targets 10 major Indian languages alongside English, proving that thoughtful design can outperform brute force. The model’s innovative approach tackles two critical challenges: token efficiency and data quality.
Traditional multilingual models struggle with Indic scripts, requiring up to 8 tokens per word compared to English’s 1.4. Sarvam-1’s optimized tokenizer slashes this to 1.4-2.1 tokens across all supported languages, dramatically improving efficiency. The team also addressed the chronic shortage of high-quality Indian language data by developing advanced synthetic data generation techniques, creating a robust 2-trillion token training corpus.
Despite its relatively modest size, Sarvam-1 is punching well above its weight. It outperforms larger models like Gemma-2-2B and Llama-3.2-3B on standard benchmarks while matching Llama 3.1 8B’s capabilities. This efficiency translates to 4-6x faster inference speeds, making it ideal for practical applications and edge devices. The model’s success demonstrates that careful optimization and focused development can often outperform sheer computational power.
EDITOR NOTE: As an Indian, myself I am very intersted and exited for this project, it is a great step towards using multilingual models for Indian languages. I also think that this will make increase the overall quality of the model for even english data. I am very excited to see the results of this project.
Video Generation Breakthroughs: Mochi and Act-One
The video generation landscape is seeing remarkable advancement with two significant releases. Mochi 1, released under the Apache 2.0 license, represents a state-of-the-art open video generation system that dramatically narrows the gap between closed and open systems. Its high-fidelity motion and strong prompt adherence capabilities mark a significant milestone in democratizing video generation technology.
link to the video: here
Meanwhile, Runway’s Act-One introduces a novel approach to character animation. The system generates expressive character performances using just a single driving video and character image, eliminating the need for complex motion capture or rigging processes. This development in Gen-3 Alpha could revolutionize character animation workflows, making sophisticated animation techniques accessible to a broader range of creators.
Granite 3.0: IBM’s Open Source Innovation
IBM’s latest release of Granite 3.0 under the Apache 2.0 license represents a significant advancement in foundation model development. The lineup includes highly efficient 8B and 2B models that outperform similarly-sized competitors, alongside innovative 1B and 3B Mixture of Experts (MoE) models that achieve remarkable results with just 400M and 800M active parameters respectively.
What sets Granite 3.0 apart is its focus on efficiency and accessibility. The 1B and 3B MoE models are specifically designed for on-device applications, making advanced AI capabilities available in resource-constrained environments. IBM has also taken the unprecedented step of providing detailed technical documentation for training an 8B model from scratch, fostering transparency and enabling broader participation in AI development.
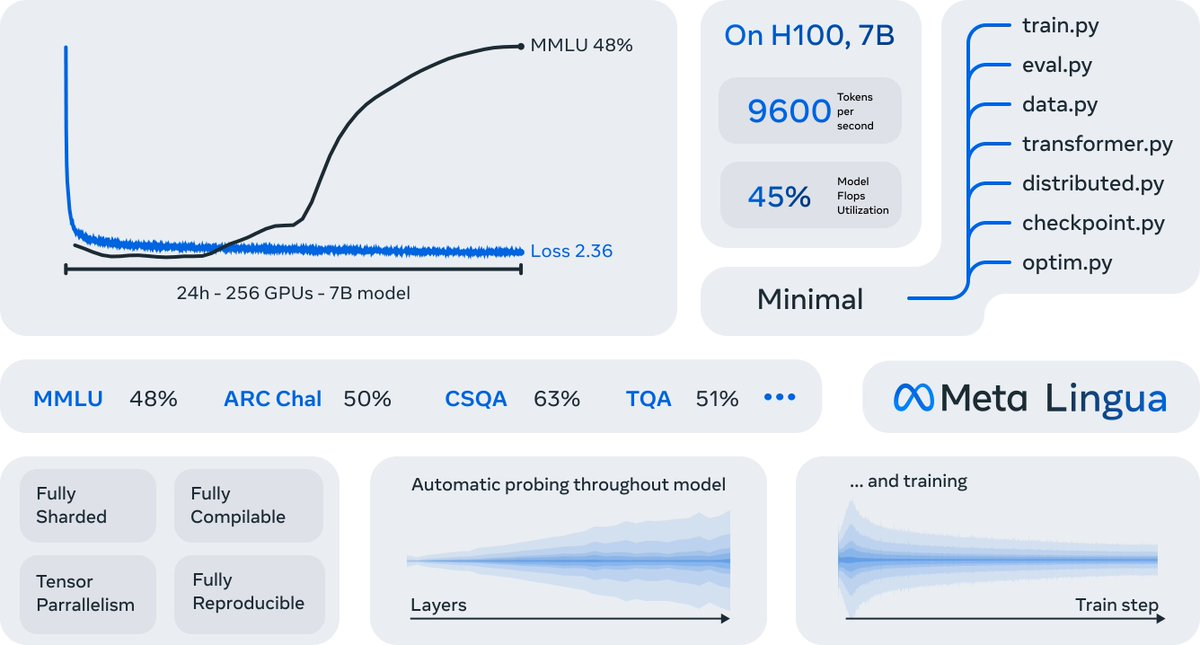
Meta Lingua: Democratizing LLM Training
Meta has made a significant contribution to the AI community with the release of Meta Lingua, a lightweight and self-contained framework designed for training language models at scale. This PyTorch-based codebase stands out for its research-friendly architecture, making it particularly valuable for academics and researchers looking to experiment with new model architectures, loss functions, and data processing techniques.
What makes Meta Lingua particularly noteworthy is its modular design philosophy. The framework uses easy-to-modify PyTorch components, enabling researchers to quickly iterate on different aspects of model development without getting bogged down in implementation complexities. This approach democratizes LLM training by providing a flexible, yet powerful foundation for exploring new ideas in language model development.
The release reflects Meta’s commitment to open research and collaborative AI development, providing the AI community with tools previously limited to large tech organizations. By making such sophisticated training infrastructure freely available, Meta Lingua could accelerate innovation in language model development and help bridge the gap between academic research and industrial applications.